Why Transformers are Slowly Replacing CNNs in Computer Vision?
Why Transformers are Slowly Replacing CNNs in Computer Vision?
Before getting into Transformers, let’s understand why researchers were interested in building something like Transformers inspite of having MLPs , CNNs and RNNs.
- Transformers were originally designed to help Language Translation. Transformers enable modelling long dependencies between input sequence elements and support parallel processing of sequence as compared to recurrent networks e.g., Long short-term memory (LSTM)
- The straightforward design of Transformers allows processing multiple modalities (e.g., images, videos, text and speech) using similar processing blocks.
Everyone wants a universal model to solve different tasks with accuracy and speed. Just like MLPs which are universal function approximators, Transformer models are universal approximators of sequence-to-sequence functions.
Transformers use the concept of Attention mechanism. Let’s look what is attention and briefly go through self attention mechanisms.
Attention Mechanism
Attention mechanism enhances the important parts of the input data and fades out the rest. Take the example of you captioning an image. You will have to focus on the relevant part of the image to generate meaningful captions. This is what Attention mechanisms do.
But why we need attention and all, CNNs are pretty good at feature extraction, Right?

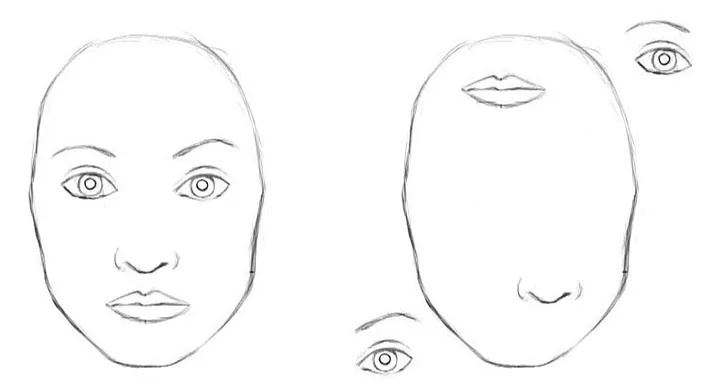
For a CNN, both of these pictures are almost same. CNN does not encode the relative position of different features. Large filters are required to encode the combination of these features. For examples:- to encode the information “eyes above nose and mouth” require large filters.
Large receptive fields are required in order to track long-range dependencies within an image. Increasing the size of the convolution kernels can increase the representational capacity of the network but doing so also loses the computational and statistical efficiency obtained by using local convolutional structure.
Self-Attention modules, a type of Attention Mechanism, along with CNN helps to model long-range dependencies without compromising on computational and statistical efficiency. The self-attention module is complementary to convolutions and helps with modeling long range, multi-level dependencies across image regions.

Here you can see a self attention module replaces the convolutional layer, so that now the model gets the ability to interact with pixels far away from its location.
More recently, researchers ran a series of experiments replacing some or all convolutional layers in ResNets with attention, and found the best performing models used convolutions in early layers and attention in later layers.
Self Attention
The self-attention mechanism is a type of attention mechanism which allows every element of a sequence to interact with every others and find out who they should pay more attention to.

It allows capturing ‘long-term’ information and dependencies between sequence elements.
As you can see from the image above, “it” refers to the “street” and not “animal”. Self-attention is a weighted combination of all other word embeddings. Here the embedding of “it” is a weighted combination of all other embedding vectors, with more weightage on the word “street”.
To understand how the weighting is done, watch — https://www.youtube.com/watch?v=tIvKXrEDMhk
Basically, a self-attention layer updates each component of a sequence by aggregating global information from the complete input sequence.
So here we just learned how an attention mechanism like self attention can effectively solve some of the limitations of the Convolutional Networks. Now is it possible to entirely replace the CNN’s with an attention based model like the Transformers?
Transformers have already replaced the LSTMs in the NLP domain. What is the possibility of the transformers replacing the CNN’s in computer vision. What are the approaches built with attention which have outperformed CNNs. Let’s look into that!
The Transformer Model

The Transformer model was first proposed for solving NLP tasks mainly Language Translation. The proposed Transformer model has an encoder-decoder structure. Here, the picture on the left shows an encoder and the right is a decoder. Both the encoder and the decoder has self attention layers , linear layers and residual connection as shown.
Note : In convolutional networks, feature aggregation and feature transformation are simultaneously performed (e.g., with a convolution layer followed by a non-linearity), these two steps are done separately in the Transformer model i.e., self-attention layer only performs aggregation while the feed-forward layer performs transformation.
The encoder
Take the case of language translation itself. The self attention mechanism in encoder helps the inputs(words) to interact with each other, thereby creating a representation for each token(word) that has semantic similarity between other tokens(words).
The Decoder
The decoder’s job is to output the translated word one at a time attending on both input embeddings and outputs generated so far.
The Decoder outputs one word at time by concentrating on specific parts of the encoder outputs and by looking at the previous outputs generated so far. To ensure that the decoder looks only at the previous outputs generated and not at the future outputs during training, Mask Self Attention mechanism is used in the decoder. It just masks the future words given at the input of the decoder during training.
Self attention doesn’t care about position. For example in the sentence “Deepak is the son of Pradeep”. Consider that the SA gives more weightage to the word “Deepak” for the word “son” . If we shuffle the sentence, say “Pradeep is the son of Deepak”, the SA still weigh “Deepak” more for the word “son”. But here we want SA to weigh “Pradeep” more for the word “son”.
This happens because the Self attention module produces the encoding for the word “son” by a weighted combination of all word embeddings without knowing its position. So shuffling of the tokens does not create any difference. Or in other words SA is permutation invariant. Self-attention is permutation-invariant unless you add positional information to each token before passing the embeddings to the SA module.
Vision Transformer

Vision Transformer is an approach to replace convolutions entirely with a Transformer model.
Transformer always operates on sequences, thats why we split the images to patches and and flattening each such “patch” to a vector. From now i would call a “patch” as a token. So now have a sequence of tokens.
The self attention is by design is permutation invariant. Self-attention “generalises” the summation operation as it performs a weighted summation of different attention vectors.
Invariance under permutation means that if you present a vector as an input — say [A, B, C, D] — the network should output the same result as if you had input [A, C, B, D], for instance, or any other permutation of vector elements.
So positional information is added to each token before passing the whole sequence to the self attention module. Adding positional information will help the transformer understand the relative position of each tokens in the sequence. Here positional encodings are learned instead of using standard encodings.

Finally output of the transformer from the first position is used for further classification by an MLP.
Training the transformers from scratch requires a lot much data than CNN. This is because CNNs encode prior knowledge about the image domain like translational equivariance. Transformers on the other hand has to learn these properties from the data given.
Translational equivariance is a property of convolutional layers where the feature layer will have an activation moved to the right, if we shift the object to the right in the image. But they are “really the same representation”.
ConViT
Vision Transformer , entirely provides the convolutional inductive bias(eg: equivariance) by performing self attention across of patches of pixels. The drawback is that, they require large amount data to learn everything from scratch.
CNNs performs better in the low data data regimes due to its hard inductive bias. Whereas when a lot of a data is available, hard inductive biases(provided by CNNs) is restricting the overall capability of the model.
So is it possible to obtain the benefits of the hard inductive bias of CNN’s in low data regimes without suffering from its limitations in large data regimes?
The idea is to introduce a Positional Self Attention Mechanism(PSA) which allows the model to act as convolutional layers if needed. We just replace some of the Self attention layers with PSA Players.
We know positional information is always added to the patches since SA are permutation invariant otherwise. Instead of adding some positional information to the input at embedding time before propagating it through the Self Attention layers(like in Vit), we replace the vanilla Self Attention with positional self-attention (PSA).
In PSA, you can see Attention weights are calculated using relative positional encodings(r) and a trainable embedding(v) also. Relative positional encodings(r) depend only on the distance between the pixels


These multi-head PSA Layers with learnable relative positional encodings can express any convolutional layer.
So here we are not combining CNNs and attention mechanisms. Instead we use PSA Layers which have the capability to act as Convolutional Layers by adjusting some parameters. We are utilising this power of the PSA layers at initialisation. In small data regimes, this can help the model to generalise well. Whereas in large data regimes, the PSA layers can leave its convolutional nature if needed.
Conclusion
Here we show that, Transformers originally developed to solve Machine Translation is showing good results in computer vision. ViTs outperforming CNNs for image classification was a major breakthrough. However, they require costly pre-training on large external datasets. ConViT, outperforms the ViTs on ImageNet, while offering a much improved sample efficiency. These results show that Transformers have the capability to overtake CNNs in many computer vision tasks.
References
Transformers in Vision — https://arxiv.org/pdf/2101.01169.pdf
ConViT — https://arxiv.org/pdf/2103.10697.pdf
Don’t forget to give us your 👏 !
![]()